Vector 4 Keyboard
I have a Vector 4 manufactured by Vector Graphic, Inc. It’s an old machine from the 80s that happily still runs. Or at least one out of two I have still runs.
I’ve been on a long escapade trying to preserve the device as there’s very little information archived for it online. This has included adding hard sector and Micropolis support to FluxEngine and hard sector support and async I/O handling to FlashFloppy.
In 2020 I was trying to use the machine and the keyboard wouldn’t work. The keyboard has foam pads with one conductive side and the foam had disintegrated. Thankfully other keyboards from the era, much more common than mine, have suffered the same fate and TexElec sells replacements. They are a bit finiky so some keys won’t work and I have to reopen the keyboard (with over 20 screws) to fiddle with the pads. But all the keys are currently working. Great.
But the keyboard isn’t that great to type on. It works, but pales in comparison to cheap keyboards today. How hard would it be to make an adapter to use a “modern” USB or PS/2 keyboard? The keyboard’s operation isn’t documented anywhere to my knowledge, but I figured it’d be quick to reverse engineer.
The keyboard connects to the computer with a 6P6C connector, and a board in the machine has helpful labels. The 8P8C connector is on the bottom left; ignore the pin numbers, except pin one.

Following the traces, we get:
| Pin | Assignment |
|---|---|
| 1 | GND |
| 2 | GND |
| 3 | GND |
| 4 | +5V |
| 5 | S OUT |
| 6 | S IN |
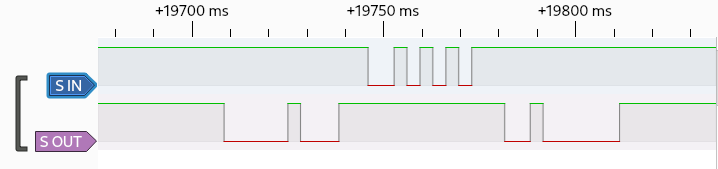
“S” would clearly mean serial, and there’s no separate clock. Maybe it’ll be like RS-232. Now let’s take a look with a logic analyzer.

Typing is at least mostly a one-way protocol. Pin is high during idle. Comparing for more button presses made the encoding clear. 0 is low, 1 is high. The bit rate is 300 Hz. It starts with a 0 bit, has 8 data bits with LSB first, and stops with a 1 bit. Data bits are ASCII characters. When holding down a key, presses are 71 ms apart. There’s no obvious source of queuing, so it’d be hard to have two letters nearer each other. My key presses are buffered, so I guess it is queued on the computer and not the keyboard. I’m not aware of an easy way to overflow that buffer as it seems to be greater than ~30 characters large. Wow. That was easy.
Now can I make a keyboard emulator? I figured I’d start with a Raspberry Pi Zero W to make entering text easy over wireless. Python should be easy, and 3ms timings seem like something it could probably handle. A quick script later and… it doesn’t work. Looking at the logic analyzer shows really bad timing. Oh well… let’s port it to Go. Surely a quick go program will work. Nope. Still poor timing. Much better. But not good enough. Busy looping and nice levels didn’t help. Shucks.
Well, I was wanting a project to use a Raspberry Pi Pico. It has micropython; I wonder what that’s like. A quick port to micropython and… it works! The computer displays “KBD error”, but the keyboard works regardless.
What’s the point of S OUT? Just after cold boot starts the computer sends 0x08 (BS?). But there’s no response. Later the computer sends 0x10 (DLE? surely not), the keyboard replies 0xAA, and the computer sends 0x02 (STX?). That exchange seems to be the KBD test and can be triggered separately with a ‘T’ Test mode instead of the normal HDD or FDD bootup. The keyboard beeps during this exchange. After pressing ‘W’ to choose to boot from the “Winchester” HDD the computer sends 0x02 (STX?). Also no response. Seems S OUT data is some custom meaning and just uses powers of two. The 0xAA response has alternating bits so is good for testing.
The Raspberry Pi Pico isn’t 5V tolerant, so I won’t bother any more with S OUT. USB or PS/2 can be for some other day, but it is quite feasible.
In a follow-up post I make the adapter.
Hosting my own SMTP server
I discussed previously how I found myself searching for a way to provide email notifications from my servers. I had previously been using my Gmail account, and I realized I didn't want the servers to have access to my Gmail account any longer.
Since I already had a domain name, I wanted to try out hosting an SMTP server. While the idea of self-hosting the SMTP server seemed crazy to me, for this limited use-case it actually turned out well and was relatively easy! Being counted as spam hasn't been too large a problem and the configuration wasn't too bad.
The Apprehension
I had previously hosted my own email server in 2004. And I hated it. Outgoing emails could easily be marked as spam and incoming emails were virtually all spam. It wasn't serving much purpose, so I had turned it off.
Mail transfer agents (MTAs), which is what I'm needing here, are also notoriously obscure and complicated to configure properly. There are also many to choose from and there's generally no "cookie cutter" configuration, so the task requires learning a reasonable amount each option in order to determine a preference. I'm maybe willing to learn one, but I'd rather not sink a bunch of time into an option just to discover I hate it. Or that I hate all the options.
I had also expected things had gotten worse since I last delved into it, since there's been new standards to address spam and I have little idea how they work, although I know some use cryptography. Given how painful TLS is to configure (and how painful it was to get a certificate before Let's Encrypt), that sounds awful.
Virtually everyone on the Internet agrees that the best way to avoid ending up in the spam folder is to use a well-established email provider. I need this for possibly-important notification emails; I will have a very low tolerance for them going to spam. I worried even after all the effort of setting things up, too many emails go to spam and I have to scrap it.
SPF (IP Whitelist)
As part of my research, I had taken took a quick glance at SPF. It was easy enough that I set it up immediately. SPF is simply a whitelist of IP addresses that send email for your domain, and published via DNS.
The detailed record
syntax is a good reference after you see an example. You publish it as a TXT
record for your domain. So I had a TXT for @ for my ersoft.org
domain. A simple value to say "mail should come from IP 1.2.3.4" would be
v=spf1 ip4:1.2.3.4 ~all.
Since explicitly listing IP addresses is annoying to update, you can refer
to a hostname with something like a:example.ersoft.org. You can
also refer to servers in your MX records with mx. And you simply
list multiple things before the ~all to allow them, like
v=spf1 ip4:1.2.3.4 ip4:1.2.3.5 a:example.ersoft.org mx ~all.
If you want to see published values for various domains (or your own), you
can use dig via dig ersoft.org txt.
You should probably avoid the stricter -all. Legitimate email
forwarding by others breaks SPF. For example, I can use Google
Domain's email forwarding feature to forward ejona@ersoft.org to my Gmail
account. If you send an email to ejona@ersoft.org, that email would be
forwarded to my Gmail account by a Google Domain server with you as the sender.
But your SPF policy doesn't allow Google Domains to send emails for your
account, so your SPF will fail because of my configuration. And if you have
DMARC enabled, you'd receive failure reports. This is a fatal flaw of SPF. And
so we limit the negative impact of SPF with ~all.
OpenSMTPD
As I glanced at various SMTP servers, I came across a two-line configuration snippet on the Arch Linux wiki for an OpenSMTPD server acting as a mail relay. It seemed pretty comprehensible so trying out OpenSMTPD seemed worth a try. And it turned out great.
The smtpd.conf documentation is really nice. Between the default smtpd.conf and it I quickly had my initial configuration, which was simply:
listen on localhost
table white-sender {"@ersoft.org"}
table white-recipient {"example@gmail.com", "@ersoft.org"}
accept sender <white-sender> for any recipient <white-recipient> tls verifyI was very concerned about being marked as a spammer, so I wanted the white lists before any testing. It would have been very easy to have test emails that were "bad" (like wrong "from" address) and I didn't want those to go to Google. So the configuration only listens on localhost and only allows outgoing mail from ersoft.org addresses to the whitelisted Gmail account or to my domain.
I needed a test command. I used:
echo "Subject: sendmail test; unique-test-desc" | \
sendmail -v -f noreply@ersoft.org example@gmail.com
And it failed! But with a helpful link to Google's Guidelines for IPv6. I was actually really happy to see this, because the documentation was really helpful for more than IPv6.
So the problem was that IPv6 requires PTR records. While I may mess
with that eventually, I don't want to do it out-of-the-gate. So I limit myself
to using IPv4 by adding a configuration line: limit mta inet4. And
then my test email arrived! (Note: I already had SPF configured here; I don't
know how important it was.)
At this point there's an email in my inbox that I can inspect. In the email drop-down menu I clicked "Show original" to see the raw MIME email. This was helpful to see that the sender and receiver were correct. But looking at "Authentication-Results" was also helpful. In this email, I saw a "spf=pass" with some additional information that is useful for debugging. I was also able to confirm TLS was used by seeing "version=TLS1_2 cipher=ECDHE-RSA-AES128-GCM-SHA256" in the "Received"). When you get there, you can also use it for DKIM and DMARC debugging. If you are new to email, understand that each server the email passed through will prepend additional headers. So, for example, there are generally multiple "Received" headers, and the topmost one was added by the last server.
That was really easy! Now it was iteration and improvement.
DKIM (Cryptographic Message Signing)
DKIM is a signature-based mechanism to prove that an email originated from a particular source. Interestingly, DKIM can be used to sign emails even if the email being signed is from a different domain. This allows Gmail, for instance, to send an email impersonating an @ersoft.org address, but the DKIM would show it coming from a gmail.com server. So the receiver would then have a clear view: ersoft.org did not send the email, but if gmail.com is reasonably trusted, it can be accepted anyway.
DKIM publishes public keys via DNS as a subdomain of the _domainkey subdomain. The creation and publishing of keys is fairly easy, especially compared to things like TLS. Most of the effort comes from configuring your server to provide the signatures using they key, and that's not onerous.
OpenSMTPD provides an example using dkimproxy and dkimproxy provides reasonable documentation. Note that Google suggests using 2048 bit keys, so you may want to use "2048" instead of the "1024" in the "openssl genrsa" command when following the dkimproxy documentation.
I used a dkimproxy_out.conf like:
listen 127.0.0.1:10027
relay 127.0.0.1:10028
domain ersoft.org
keyfile /etc/dkimproxy/private.key
selector example
"Selector" would match the DNS name used, so "example._domainkey.ersoft.org"
(which doesn't exist) in this case. You can use dig via dig
example._domainkey.ersoft.org txt.
Unlike the example documentation, I'm using filtering, so I found it useful
to use tagged ! DKIM since otherwise it seemed possible to form an
infinite loop:
listen on localhost
listen on localhost port 10028 tag DKIM
...
accept tagged DKIM sender <white-sender> for any recipient <white-recipient> tls verify
accept tagged ! DKIM from local for any relay via smtp://127.0.0.1:10027Note that I'm filtering after adding the DKIM signature. Since it is possible for someone on the same machine to write to dkimproxy directly, I am considering the results from the proxy "untrusted."
DMARC (Enforcement and Reporting)
DMARC specifies what to do with emails that have SPF or DKIM issues and how to report them, published via DNS. For instance, if you misconfigured your SPF and Google was flagging emails, you'd like to be notified instead of just happening to notice emails were being rejected. While the DMARC standard allows for multiple types of notifications, the main option is to specify an email address that should receive aggegrated daily digests independent of whether there are problems. Since that'd be annoying to go to a personal email account and you really need to process the raw data, there are services that you can route these emails to and can provide pretty graphs.
DMARC also uses a TXT record in DNS, but with the _dmarc subdomain (so
_dmarc.ersoft.org for me). If you are comfortable with your setup, a strict
value would be v=DMARC1; p=reject; rua=mailto:example@ersoft.org
with a proper email address. The standard
disallows
reporting emails to go to a different domain, but that is different from an
earlier draft and I suspect servers may allow it anyway. But I've also not
needed to investigate this for my set up. I found
G Suite's
documentation to be most clear in describing the useful options.
If you want to see published values for various domains (or your own), you
can use dig via dig _dmarc.ersoft.org txt.
Final notes
To support extra machines, you can either set up each with it's own server (and its own DKIM selector), or you could allow them to use the first machine's SMTP server. I went with the latter option. I considered using client certificates, but simple username/password seemed about as effective and easier to setup and manage.
If using Let's Encrypt for TLS certs, note that OpenSMTPD is particular
about the permissions of the private key file. You can fix the permissions via
chmod o-r /etc/letsencrypt/live/example.ersoft.org/privkey.pem.
You can configure /etc/letsencrypt/renewal/example.ersoft.org.conf
to include a renew_hook within [renewalparams] to
automate the "fix".
Also, if you're interested in using file-based tables in OpenSMTPD, I'll
note that smtpctl update table <tablename> didn't actually work
for me. I just restart OpenSMTPD instead.
The search for XOAUTH2 for notification emails
I've been using sSMTP with Gmail for a few years to be notified of cron job failures and automatic bans. It's reasonably easy to set up, but I wanted to improve the security. Through a series of dead-ends, I eventually found myself setting up my own outgoing mail server, and found it pretty easy once shifting through all the noise.
The Appeal
I've had two factor authentication enabled on my Gmail account since 2011. Thus I'm familiar with "App Passwords:" Google-generated passwords that are limited to a few services (like SMTP and IMAP), but can't directly log in via the web interface.
App Passwords have always been a last resort and so there's a drive to replace them with more secure methods like OAuth, but it's a slow process. I care about the security of my Gmail account and am interested in "best practices," so I'd been looking to migrate to XOAUTH2 for a few years now. With something like OAuth, you can restrict usage to just certain operations, like sending email.
During a recent trip to my Google account settings I noticed the App Passwords still there, and renewed an interest to replace them.
As is probably true for many people, if someone got access (even just read access) to my Gmail they could do a lot of harm. They could use the "I forgot my password" feature on many websites to reset passwords, see the confirmation email send to my inbox, and then change the password to something they know.
A long way to an unexpected dead-end
It's been several years since I had last investigated, so I hoped for some progress. I was only to be disappointed.
I first checked whether sSMTP supported them, but no, it only supports LOGIN and CRAM-MD5. So I then searched to figure out if there was any work to add it, or what problems had been encountered.
What I found was that sSMTP is basically unmaintained and a weird project to begin with, as it never really evolved out of its Debian maintenance. It's official webpage is the Debian package tracker, the bug tracker is the Debian bug tracker, and the source repository is the Debian package source repository. It does seem various people exchange patches as necessary, but it isn't close to vibrant development.
I searched for alternative /usr/bin/sendmail replacements, but
they all seemed to be much bigger, full-blown mail transfer agents (MTA) like
sendmail itself. I wanted something small and simple. And it didn't seem they
supported XOAUTH2 to boot.
Back on sSMTP, I found an interesting Git repo, but it didn't yield too much in the end. And I also found a bug, with a patch attached, to add SASL support. If an application supports a SASL library, the SASL library is able to add new authentication mechanisms without needing to modify the application. So this could be a way to get XOAUTH2.
So I searched for SASL support for XOAUTH2. I basically only found cyrus-sasl-xoauth2 . But it requires having a file with the OAuth tokens stored in it! Those tokens expire after an hour or so, so this proved to be near useless. There's not even SASL support for XOAUTH2.
I considered writing the support myself. The annoying part would be the OAuth token. I'd need to find a library to help me retreive it in C, and I'd probably want to cache the OAuth token as a file. Basically, the same part the SASL implementation avoided.
I also considered writing my own SMTP client. Doing it in either Python or Go seemed relatively easy. Neither library supports XOAUTH2, but it'd be just a bit of glue code to combine with existing OAuth APIs. But this also required making a mailx/sendmail emulating executable, which would be tedious due to the number of flags.
And then I stumbled on the realization that XOAUTH2 provides little
improvement.
SMTP access requires the https://mail.google.com/ scope
(https://www.googleapis.com/auth/gmail.send is insufficient), and
that provides
Full access to
the account. Even with XOAUTH2 I can't limit access to just sending email!
So it's not worth any effort for me. I'm sure glad I didn't realize that after
a bunch of coding!
Alternatives
I considered writing my own mailx/sendmail emulation executable that used the Google-native mail sending API. This is basically equivalent to one of the earlier ideas, but using a different protocol which would only need the "send email" scope. The OAuth token wouldn't be able to read my email. But this would have the same annoyance of needing to make a mailx/sendmail emulating executable. I was also beginning to consider the damage that someone could do with just email sending access to my account.
I realized this was all a massive workaround. I really wanted a solution where the machines had no access to my Gmail account. The normal solutions here would be to:
- Use the SMTP server provided by my ISP. I think this would have been possible 2 years or so ago, but it doesn't appear I can set this up any more.
- Make a robot Gmail account. Just a trash account that does nothing but send me these emails. This would have been easy, but I have an aversion to creating trash accounts and wanted a "real" (or maybe "pure") solution.
- Pay a provider. This would have been fine, but in 5 minutes of searching didn't see any super-cheap providers (say, less than $5 a month), and it is little different from the robot Gmail account.
But I instead went the seemingly-crazy route of hosting my own SMTP server. And it turned out not be so bad.
Google Authenticator
I have been happily using two-factor authentication with my Google account for months. I appreciate the added security and it hasn't been much hastle.
I decided it would be a good idea to implement something similar for access to my server. There are several options available, but I selected using pam_google_authenticator. It integrates with the Google Authenticator phone application and supports backup OTPs for when your phone is unavailable.
Since I am using Arch, the process begins with installing the
google-authenticator-libpam-hg package from AUR. Normally this would be
an easy task, but for some reason hg clone fails during building. I
worked around the problem by running hg clone
https://code.google.com/p/google-authenticator command manually in my
home directory, and then creating a symlink to it for use in the build
script. I also installed qrencode for generating QR codes.
Now that it is installed, you have to configure PAM to make use of the new
module. I created a new file /etc/pam.d/google-authenticator with
the contents:
#%PAM-1.0 auth sufficient pam_access.so accessfile=/etc/security/access-local.conf auth sufficient pam_succeed_if.so user notin some:users:here auth required pam_google_authenticator.so
The pam_google_authenticator module does the real work, but
there are only two cases that I want to require the OTP. I want to require the
OTP for all connections from the Internet, but not my LAN. Thus
pam_access, with the help of additional configuration, does just
that. When turned on, pam_google_authenticator requires all users to use OTP
with no provision for users who haven't setup their two-factor authentication
yet (it would simply prevent them from logging in). There are several patches I
could have applied to fix this problem, but I just went with the simple approach
of manually configuring the list of users I want to use two-factor
authentication with the pam_succeed_if module.
some:users:here is a colon-separated list of users that will be
using two-factor authn.
For pam_access, I created /etc/security/access-local.conf:
+ : ALL : 10.0.0.0/24 + : ALL : LOCAL - : ALL : ALL
The first line is where you define your network's subnet. It should likely be
something like 192.168.1.0/24.
To allow PAM to query additional information via SSH, you need to make sure
that ChallengeResponseAuthentication is not set to no
in /etc/ssh/sshd_config. The default is yes, but in
Arch they set it to no, so I just commented out that line in the
config and restarted SSH.
As my normal user, I ran google-authenticator which generated a
TOTP secret in my home directory. (Assumably) since I had qrencode installed, it
also provided a very nice QR code (in the termal even!) that I scanned with my
phone to configure the Google Authenticator Android application.
All the preparation work is complete, I now need to enable the setup for ssh.
In /etc/pam.d/sshd I added a line under auth required
pam_unix.so ...:
auth substack google-authenticator
After a bit of testing, I verified everything was running as I expected and
I now have two-factor authentication for accessing my server via SSH. To
enable two-factor for additional accounts I will have the account user run
google-authenticator and setup their phone, after which I will add
them to the list passed to pam_succeed_if.
XSLT with Python
I just thought it had been a long time since my last post. This one wins even more.
I still really like Lighttpd and until recently was only using Apache for mod_svn and mod_xslt. I don't have much choice with mod_svn short of using svnserve (which I may end up doing), but a few months ago (December 12 by the file date) I took up the challenge of replacing mod_xslt.
I did enjoy mod_xslt and can't complain about its performance or memory usage. The fact that the project is dead is disconcerting, but any time the module stops compiling I'm able to get it working again by looking around, posting on the mailing list, or fixing it myself. Really, the only real qualm I have is that it requires Apache.
As an aside, my love for XML has long since passed and so I just want the system to work and I won't make any future enhancements. In general, I am now anti-XML and pro-JSON and -Bencode. My opinion is that there are still uses for XML, but that it is generally overused.
After some time, I developed this CGI script in Python:
#!/usr/bin/env python
from lxml import etree
import cgi
import sys, os
KEY="SOMESECRETKEY"
def transform(xml, xslt):
doc = etree.parse(xml)
doc.xinclude()
style = etree.XSLT(etree.parse(xslt))
return style.tostring(style.apply(doc))
if __name__ == "__main__":
import cgitb
cgitb.enable()
form = cgi.FieldStorage()
if "key" not in form or form["key"].value != KEY:
print "Status: 403 Forbidden"
print "Content-Type: text/html"
print
print "<html><title>403 Forbidden</title><body><h1>403 Forbidden</h1></body></html>"
sys.exit()
xml = form["xmlfile"].value
xslt = form["xsltfile"].value
contenttype = form["contenttype"].value
print "Content-Type:", contenttype
print
print transform(xml, xslt)
Luckily I didn't use very many mod_xslt specific features, so everything seemed to "just work." I did lose Content-Type support, so I have to hard-code it as a GET parameter. Notice I added the secret key in there since I didn't want to bother with proper security.
Now for the Lighttpd configuration. Since I can no longer use .htaccess files in different directories to change which XSLT is used, I get this more-ugly config:
url.redirect = ( "^/$" => "/recent/" )
url.rewrite-once = (
"^(/recent/rss/)(?:index.html|index.xml)?$" => "/cgi-bin/ejona-xslt.py?key=SOMESECRETKEY&xsltfile=/path/to/htdocs/shared/xsl/application-rss%%2Bxml.xsl&contenttype=application/xml&xmlfile=../$1/index.xml",
"^(/recent/atom/)(?:index.html|index.xml)?$" => "/cgi-bin/ejona-xslt.py?key=SOMESECRETKEY&xsltfile=/path/to/htdocs/shared/xsl/application-atom%%2Bxml.xsl&contenttype=application/atom%%2Bxml&xmlfile=../$1/index.xml",
"^(/recent/atom/summary/)(?:index.html|index.xml)?$" => "/cgi-bin/ejona-xslt.py?key=SOMESECRETKEY&xsltfile=/path/to/htdocs/shared/xsl/application-atom%%2Bxml.summary.xsl&contenttype=application/atom%%2Bxml&xmlfile=../$1/index.xml",
"^(/recent/atom/0\.3/)(?:index.html|index.xml)?$" => "/cgi-bin/ejona-xslt.py?key=SOMESECRETKEY&xsltfile=/path/to/htdocs/shared/xsl/application-atom%%2Bxml.0.3.xsl&contenttype=application/xml&xmlfile=../$1/index.xml",
"^((?:/recent/|/archive/).*).(?:html|xml)$" => "/cgi-bin/ejona-xslt.py?key=SOMESECRETKEY&xsltfile=/path/to/htdocs/shared/xsl/text-html.xsl&contenttype=text/html&xmlfile=../$1.xml",
"^((?:/recent|/archive)/(?:.*/)?)$" => "/cgi-bin/ejona-xslt.py?key=SOMESECRETKEY&xsltfile=/path/to/htdocs/shared/xsl/text-html.xsl&contenttype=text/html&xmlfile=../$1/index.xml",
)
index-file.names = ( "index.xml" )
Notice the %%2B's in some of the URLs. Those make it additionally ugly, but I still prefer that stuff over dealing with Apache.
All-in-all, it feels like a reasonably hackish solution, but it works great. I don't care about loss in performance (honestly, who reads a not-updated-in-over-two-years blog?) and if I really care I could convert the script into a Fast-CGI on WSGI script. It is nice to know that this proof-of-concept of a blog is somewhat portable now.